What is sharding, and how does it work?
Learn how sharding splits data across nodes to scale reads and writes. Explore hash, range, and directory approaches, key risks, and when to shard or avoid it.

Sharding is a database architecture pattern that involves horizontal partitioning, where a large dataset is split into smaller, independent pieces called shards, which are stored on different database nodes. Each shard holds a subset of the overall data, but uses the same schema as the others. In essence, each shard is a horizontal slice of the data, as opposed to vertical partitioning, which separates columns.
Figure 1 illustrates the difference: in vertical partitioning, different columns of a table are isolated into separate tables, while in horizontal partitioning or sharding, entire rows are distributed across multiple tables or shards. Together, all shards still represent the complete dataset. Shards typically follow a shared-nothing architecture, meaning they do not share hardware or storage resources; each shard operates independently, making them more scalable.
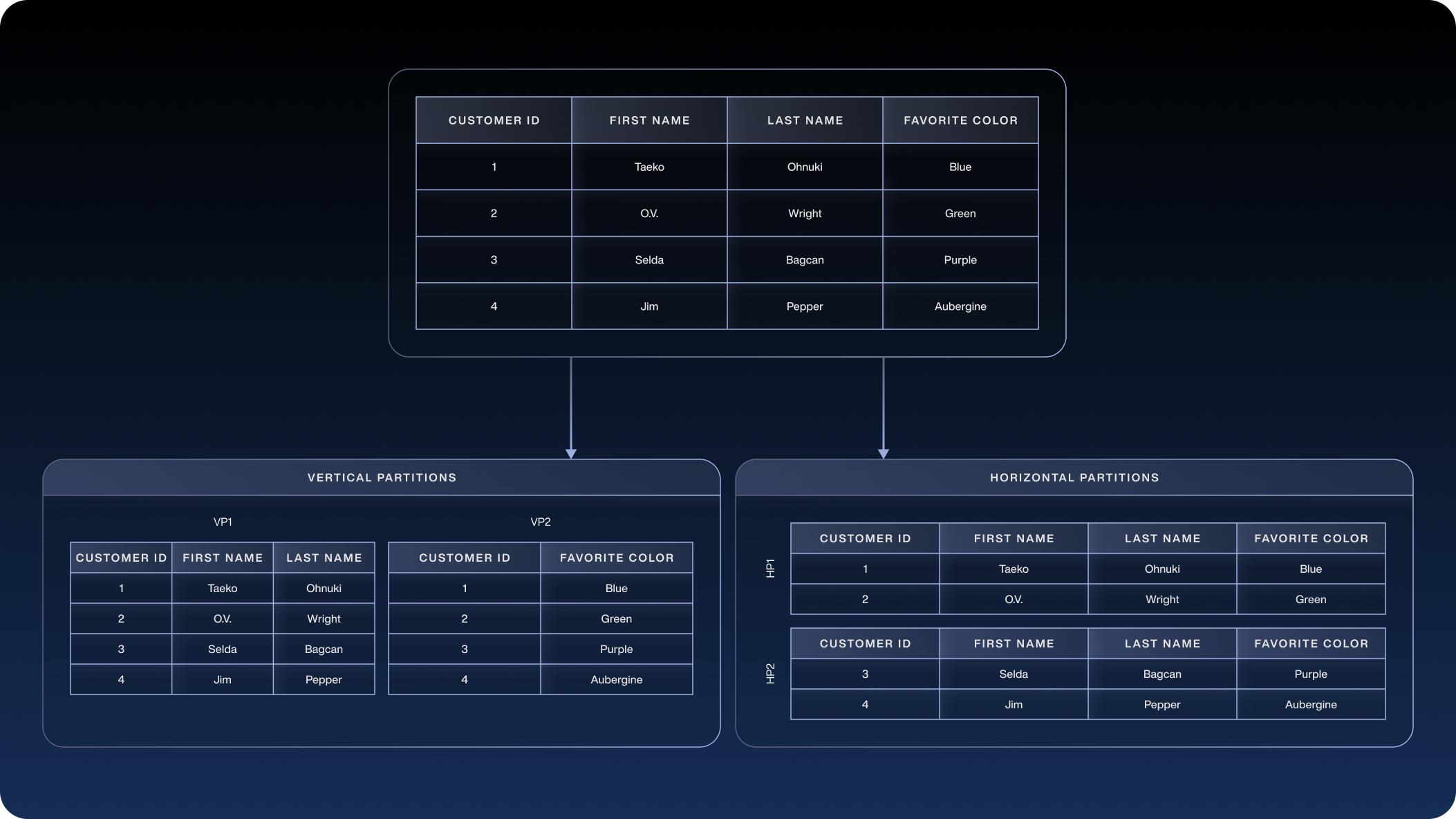
In practice, database sharding involves choosing an attribute of the data called a shard key and using it to determine how to assign each data record to a particular shard. This can be done through various methods, such as using a hash function or range criteria. By distributing data in this way, one logical database is split across multiple physical databases or nodes, each holding one shard of the data.
Some database systems require developers to implement sharding at the application level by explicitly routing reads/writes to the correct shard, while others have sharding capabilities built in at the database level. In either case, the goal of sharding is to overcome the limitations of a single-node database by scaling out across multiple machines.
Benefits of database sharding
Sharding a database offers several benefits, especially for applications dealing with large amounts of data and traffic.
Supports horizontal scaling
The primary benefit is horizontal scaling, or adding more machines to handle growth, rather than being bound to one server’s limits. Because each database shard may reside on a separate node, the overall storage capacity and compute power of the database increase linearly as you add more nodes. This contrasts with vertical scaling, or upgrading one machine’s hardware, which has finite limits. Sharding provides a clear path to handle growing data volumes and user load by scaling out the infrastructure.
Faster queries on large datasets
By breaking a large dataset into shards, queries execute on a fraction of the total data, which is often faster. In an unsharded, monolithic database, queries must scan through all records in the table, which gets slow as data grows. With sharding, queries are directed to a specific shard or shards, reducing the number of rows scanned.
For example, instead of searching a billion records in one table, a query might only search 100 million records on one shard, speeding up results. In short, sharding helps alleviate query latency issues by limiting the amount of data each query needs to search.
Better reliability and fault isolation
Sharding improves an application’s reliability and fault tolerance. In one database, if that database instance goes down, the entire application becomes unavailable. In a sharded architecture, an outage or failure on one shard’s node is likely to affect only the subset of data and users tied to that shard, while the rest of the system continues operating normally. This isolation means the overall effect of a single-node failure is much smaller because the other shards still function and keep most of the application up. In addition, because maintenance tasks or backups may be done shard-by-shard, this reduces the need for full system downtime.
Cost-effective scaling
Sharding also leads to cost benefits by using multiple commodity servers instead of pushing all the workload to a high-end machine. A cluster of smaller, commodity servers is often more cost-effective than a monolithic server with massive specs. In other words, sharding reduces the need for one large, costly server because you distribute the data across many modest servers. This not only saves on hardware but is also more flexible because you incrementally add capacity as needed. Keep in mind, though, that this may increase operational costs because of managing multiple nodes.
Challenges of sharding
While sharding has advantages, it also introduces several challenges and tradeoffs organizations must consider.
Implementation complexity and risk
Designing and implementing a sharded database architecture is complex. Partitioning data and routing application logic to multiple shards introduces a lot of new moving parts. Doing it incorrectly risks data loss or corruption during the partitioning. Even when done correctly, sharding often requires changes to how applications and developers manage data. Instead of one dataset, the team now must deal with data spread across multiple databases, which disrupts workflows and complicates operations. Debugging, backups, and schema changes become more involved. In short, sharding adds architectural complexity that demands planning, tooling, and expertise to avoid pitfalls.
Data hotspots and uneven load
Another common challenge is the potential for uneven data distribution across shards, leading to hotspots. If the sharding strategy is not well-balanced, one shard ends up storing or handling a disproportionate amount of data or traffic compared with others.
For example, imagine sharding user data alphabetically, with A-M on one database shard and N-Z on another. If many users have last names starting with “G”, the A-M shard will overload with both data and queries, while the other shard isn’t used as much. This hotspot shard becomes a performance bottleneck; it may slow down or crash under the load, which negates the benefits of sharding. In practice, poor sharding choices create hotspots that require rebalancing or resharding the data. Real-world experiences echo this: ineffective sharding often leads to data skew and overloaded nodes, making performance issues worse. Avoiding hotspots requires choosing a good shard key and sharding method so data and queries spread roughly evenly. Techniques such as hash-based sharding or consistent hashing are often used to help distribute data more uniformly.
Difficult reconfiguration or reversion
Once a database has been sharded, it can be difficult to undo or reconfigure. Merging shards back into one database or changing the sharding scheme takes time. Data that has been written after the initial sharding would not exist in older backups from the pre-sharded setup, making restoration to a monolithic architecture complicated. Essentially, sharding tends to be a one-way door; after partitioning your data, there’s no easy way to “un-shard” without major effort.
Even re-sharding by changing the shard key or splitting/merging shards differently requires migrating large amounts of data between nodes, which may mean downtime or reduced performance during the transition. This inflexibility means you must plan your sharding approach carefully up front, because reversing course later is hard.
Limited native support in some databases
Not every database technology supports sharding natively, which often forces a custom implementation. Many traditional relational databases, such as PostgreSQL, MySQL, and Oracle, do not provide automatic sharding out of the box. While a few variants or cloud offerings have introduced auto-sharding features, such as certain Postgres forks, MySQL Cluster, or managed services, such as MongoDB Atlas, standard editions typically require you to roll out your own sharding logic.
This lack of native support means you need additional application code or middleware to decide which shard to query, maintain shard mappings, and perform other operational tasks. Handling these details at the application level is more work for developers and increases the chance of errors. Moreover, tooling for monitoring or backup may not automatically work across many shards, adding operational work.
In summary, unless you are using a database system that provides built-in sharding, adopting a sharded architecture often adds operational complexity and homegrown tooling to manage multiple distributed data pieces.
Sharding strategies and architectures
Once you decide to shard your database, the next step is determining how to distribute the data across shards. The choice of sharding strategy dictates how incoming data is assigned to shards and how queries find the right shard. Here are three common sharding architectures.
Key-based (hash) sharding
In key-based sharding, also known as hash sharding, a chosen shard key from each record is run through a hash function to produce a hash value. That hash value determines to which shard the record belongs.
For example, you might designate “CustomerID” as the shard key; when a new row with CustomerID = 123 is written, the system computes a hash of 123, which might equal 0x5A, and then maps that to one of the available shards. The hash function changes the input key into a shard identifier, so any two records with the same key map to the same shard.
Because the hash randomizes the distribution, key-based sharding is more likely to spread data evenly and helps prevent any one shard from becoming a hotspot. Another advantage is that this method is algorithmic. Given the hash function, the system calculates the target shard on the fly, so it doesn’t need to keep an index or lookup table of where data is.
However, adding or removing shards dynamically is a challenge. When you add a new shard or database node to the cluster, the hash function’s range changes, meaning many existing records may need to be remapped to different shards. For instance, if you had four shards and added a fifth, the hashing scheme might change such that half of the data has to migrate. During this rebalancing, both the old and new hash assignments are in flux, making it tricky to serve writes consistently without downtime.
Some systems use techniques such as consistent hashing or fixed hash slots to mitigate this issue, but in a simple implementation, hash-based sharding may require data shuffling when scaling the cluster. The bottom line is that key-based sharding is good at evenly distributing data and avoiding manual mapping overhead, but planning is needed to scale the number of shards over time.
Range-based sharding
In range-based sharding, each shard is responsible for a continuous range of possible values based on the shard key. In other words, the data is divided by value ranges. For example, you might shard a product catalog database by price ranges: products priced $0–$100 in Shard 1, $101–$1000 in Shard 2, and so on. In this approach, the application or database router determines the range of a given record’s key and directs it to the corresponding shard. The appeal of range sharding is its simplicity; it’s straightforward to implement and understand. Each shard holds a range of data but shares the same schema, and the routing logic is usually just a lookup on the range boundaries.
However, like basic sharding, the simplicity of range partitioning does not guarantee even distribution. Hotspots are a risk because certain ranges of a dataset might get a disproportionate amount of activity.
Looking at the earlier example, if products in the $0–$100 range are more popular, that shard will receive more reads and writes than the others. Even if the ranges are defined to hold roughly equal numbers of records initially, real-world access patterns and skewed workloads lead to one shard handling most of the traffic. So range sharding suffers from the same imbalance we’re trying to avoid. It’s often chosen when the data is naturally segmented, and you can predict an even spread, but administrators must monitor for any shard growing into a hotspot over time. In summary, range-based sharding is easy to set up but requires the selection of ranges and ongoing monitoring so one shard isn’t overloaded.
Directory-based sharding
Directory-based sharding is more explicit: It uses a lookup table or directory to manage the mapping between each record’s shard key and the shard where that record resides. Essentially, a separate table, the directory, contains entries for each key or range of keys and indicates on which shard to find the corresponding data.
For example, the directory might say “UserIDs 1–10000 -> Shard A; UserIDs 10001–20000 -> Shard B; …” or maintain a list of specific keys per shard. When a query or write comes in, the system consults this lookup table to figure out the correct shard to use.
The flexibility of directory-based sharding is its biggest advantage. You are not constrained by a fixed hash function or static ranges; the mapping follows any algorithm or pattern, because it’s all recorded in the lookup table. This means you handle cases that don’t lend themselves to clean numeric ranges or uniform hashing. It’s also relatively easy to add or reassign shards in this model because you can update the directory with new mappings, such as moving a subset of keys to a new shard, without needing to re-hash everything. This dynamic nature is useful if your data distribution or access patterns change over time. For scenarios where the shard key has few distinct values or doesn’t partition well by range, a directory approach may work well.
On the downside, directory-based sharding introduces an extra lookup on every database operation, which hurts performance due to the extra indirection. Every query must first query the directory to find the right shard, adding latency. The directory itself becomes a single point of failure or bottleneck; if that lookup table is slow or goes down, your application can’t find data on shards. Additionally, maintaining the directory adds complexity; mapping must be kept consistent and updated as the dataset evolves or scales. In summary, directory-based sharding offers the most flexible data placement, at the cost of an extra metadata layer that must be fast, reliable, and well-maintained to avoid becoming a bottleneck.
When (and when not) to shard
Deciding whether to shard a database is an important architecture choice. Some experts view sharding as inevitable once an application’s data grows beyond a certain point, while others recommend avoiding it until absolutely necessary due to the complexity it adds. Both viewpoints have merit. In practice, sharding is usually considered only for very large-scale systems or when other scaling methods are no longer sufficient. Here are some common scenarios where introducing sharding may be beneficial:
Data volume exceeds a single node’s capacity: If your application’s dataset has grown so large that it can no longer fit on one database server’s storage or memory, sharding distributes the data across multiple nodes. For instance, if one machine only stores 500 GB, but you have 2 TB of data, horizontal partitioning becomes necessary.
Throughput overwhelms one server: When the rate of reads/write transactions per second is higher than what a database node and its read replicas handle, operations start timing out or slowing down. Sharding the data and traffic into multiple parallel streams with shards helps alleviate this by giving each node a smaller portion of the workload.
Network or I/O bottlenecks: In some cases, even if CPU and storage are sufficient, network bandwidth or disk I/O of one machine becomes a bottleneck, such as when a node cannot move data in/out fast enough for the application’s needs. Sharding splits the load across multiple machines and network interfaces, providing more bandwidth for data operations.
Multi-tenant isolation, which is less about performance and more about manageability: If you host data for multiple clients or user communities, you might shard by customer or tenant. This keeps one tenant’s data isolated on its own shard, improving security and giving the flexibility to place shards in different locations for compliance or performance reasons. Each tenant shard is like its own database.
That said, because of the costs and complexity of sharding, it should be a last resort after exploring simpler scaling options. Before you shard, consider strategies such as:
Moving to a dedicated or bigger server: If the database currently shares resources with other applications, migrating it to its own machine or upgrading the hardware with more RAM, CPU, or a faster disk gets more capacity without added complexity.
Read replicas / secondary nodes: Many databases allow replication of data to read-only replicas. By directing read traffic to these replicas and writes to a primary node, you scale read throughput without sharding the data at the write level. This horizontal scaling for reads delays the need for full sharding.
Optimizing queries and indexes: Sometimes performance issues can be resolved by tuning the database itself, such as by adding appropriate indexes, rewriting slow queries, or archiving old data. If high latency is due to inefficient queries or a lack of indexing, fix those first before opting for sharding.
Using these measures first is wise because once you implement sharding, you commit to the added complexity permanently. However, if your application continues to grow to the point that none of these measures keep pace with demand, then sharding might be the only viable path. At extreme scales, such as web-scale applications or massive Internet of Things (IoT) data, a well-designed sharded database architecture handles virtually unlimited growth when managed properly. The key is to plan: Choose the right sharding key and strategy, and be prepared to invest in the operational tooling and monitoring to manage a distributed data system.
Sharding and Aerospike
Sharding is a powerful technique for supporting big databases. It helps applications handle more data and higher traffic by spreading the load across many machines. However, it also introduces complexity and potential pitfalls. Many sharding challenges, from data consistency to rebalancing shards, have historically made it a difficult architecture to implement and maintain.
This is where more technologically advanced databases, such as Aerospike, come into the picture. Aerospike is a highly scalable, distributed NoSQL database built with auto-sharding and high performance in mind. In an Aerospike cluster, data is partitioned into 4,096 logical shards and distributed evenly across nodes. Developers do not need to manually devise partition keys or worry about hotspots. This gets you sharding’s benefits without the operational problems: As you add nodes, Aerospike rebalances data across the cluster, avoiding the heavy downtime or re-engineering typically associated with scaling out.
For organizations facing the limits of their current databases, whether hitting performance walls or struggling with the cost and complexity of scaling, Aerospike offers a practical path forward. Its architecture tackles many sharding challenges behind the scenes, delivering predictable low latency performance even under multi-terabyte workloads and mixed read/write conditions. If you’re looking to scale your data infrastructure without the challenges of sharding, it may be time to explore what Aerospike would do for you.